Enterprise AI Is More Than RAG: The Three Context Layers (2026)
Enterprise AI is a context orchestration problem, not a retrieval problem. Three knowledge layers, three architecture levels, the operational truth distinction.

Most enterprise AI architectures fail because they treat all enterprise knowledge as searchable documents. They wrap a chatbot around an indexed wiki, call it “AI on our data,” and discover at audit time that compliance can’t sign off, that pricing answers are wrong, and that the agent has no idea who’s actually logged in.
Enterprise AI is not a model problem. It is a distributed systems engineering problem: probabilistic orchestration of multiple state, authority, and governance domains, each with different consistency and freshness requirements. Treat it that way and the architecture clarifies. Treat it as “prompt + retrieval” and it breaks in production.
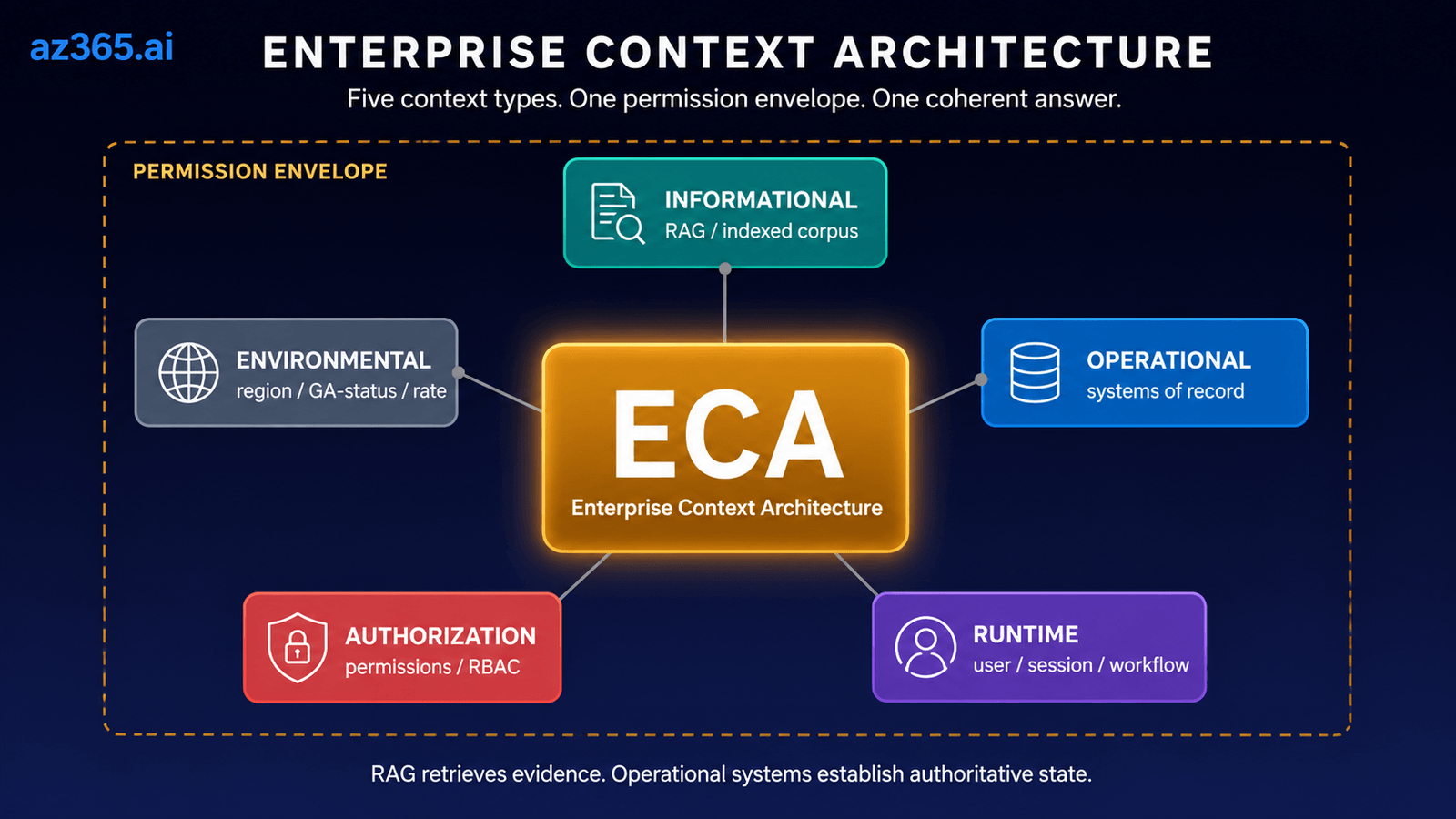
We call this Enterprise Context Architecture (ECA), and to be precise, it is broader than what vendors mean by a “context layer.” A context layer is a product; ECA is the architectural discipline of orchestrating context, authority, permissions, and execution across distributed systems. The product is a component. The discipline is the system.
ECA is not a new discipline. It is the application of existing distributed-systems patterns to the agent-architecture domain: identity propagation, service mediation, enterprise integration patterns (EIP), event-driven architecture, materialized views, retrieval orchestration. We use the name “ECA” as a working shorthand for that combined application, not as a claim to have invented these primitives. If you have built distributed systems for two decades, most of this will sound familiar; the novelty is applying that discipline rigorously to systems that include a probabilistic LLM in the call path.
There are three real levels of enterprise AI, in our read, and the differences are not depth of customization. They are differences in where the answer comes from and whether you can prove it. And the apex pattern (Level 3 + fine-tune) is not the whole story: real production systems retrieve unstructured knowledge (RAG), call structured systems of record (CRM, ERP, Dataverse), and inject runtime context (the logged-in user, the active workflow, the current session). RAG is one knowledge layer. There are three.
Microsoft’s architectural direction toward Level 3 (agentic retrieval, groundedness evaluators, Foundry IQ) is now clear. In our experience, operational maturity is still uneven: production pilots routinely hit retrieval-quality cliffs, evaluator drift between releases, and security-trimming gaps that only surface under real load. Read this article as a workload-decision frame, not a green-light to assume the Level 3 stack is plug-and-play.
What Are the Three Levels of Enterprise AI?
The three levels are out-of-box Copilot (Level 1), configured agents over approved sources (Level 2), and tailored RAG with agentic retrieval over an indexed enterprise corpus (Level 3). The distinguishing axis is not “how much AI” but how traceable each answer is back to the source it came from. In our reading of Microsoft’s 2026 surface stack, the product taxonomy maps cleanly to these three tiers. Pick your level per workload, not per organization.
| Level | Microsoft surface | Customization scope | Where the answer comes from | Traceability |
|---|---|---|---|---|
| 1. Out-of-Box | M365 Copilot Chat, ChatGPT Enterprise, generic SaaS AI | None (configuration only) | Public web + limited Microsoft Graph (your email, Teams, SharePoint with access checks) | Weak: Graph results are cited but the LLM blends them with web training data |
| 2. Configured Agents | Copilot Studio declarative agents + Power Platform connectors + Agent Builder | Knowledge sources, system prompts, connector access, topics | Approved data sources via connectors + uploaded knowledge files + Microsoft Graph | Partial: connector-source citations when retrieval triggered; topical drift outside retrieval scope |
| 3. Tailored RAG / Agentic Retrieval | Foundry agents + Azure AI Search agentic retrieval + Foundry IQ + custom RAG pipelines | Indexed enterprise corpus, retrieval design, groundedness evaluators, deterministic tool wiring | Curated and indexed enterprise knowledge corpus, retrieved per query with semantic ranking | Full: agentic retrieval returns citations + grounding data + activity arrays per response |
This is not a maturity ladder where everyone needs to climb. It is a decision frame. The right level depends on what the workload actually demands.
A note on portability. The “Microsoft surface” column names the canonical 2026 stack we work in most often, but the level pattern is vendor-portable. AWS Bedrock Knowledge Bases and Bedrock Agents map to Levels 2-3 with their own response shape. Google Vertex AI Search + Vertex AI Agent Builder cover similar ground. Databricks Mosaic AI is a Level 3 substrate with its own evaluator surface. The taxonomy is about traceability and workload fit, not Microsoft specifically. If you are not building on Microsoft, translate the pattern, not the product names.
Why Does Traceability Define Level 3?
Level 3 is defined by answers that come with their sources attached, in a format your audit committee accepts, not by “smarter answers.” Microsoft’s agentic retrieval response carries structured grounding data, citations, and execution metadata; we map that surface in pseudocode below as content, references, and activity arrays.
Microsoft’s agentic retrieval returns structured response data with three logical layers (we use these names for the pseudocode contract):
- Content: the synthesized answer, grounded in retrieved passages
- References: the source documents or chunks that grounded the answer, with citable URIs
- Activity: the retrieval plan, subqueries, ranking scores, and token-cost trace
A compliance lead reading a Level 3 response can verify each claim against its source, see what queries the system ran, and inspect the ranking that selected those passages over others. None of that exists at Level 1. Some of it exists at Level 2, inconsistently.
This is what makes Level 3 the bar for regulated workloads. Microsoft’s RAG evaluators measure groundedness (does the response cite only the provided context, or does it fabricate?) and response_completeness (did it cover all critical information from ground truth?) as first-class metrics. You can score a RAG system on those metrics the way you score functional tests, with the caveat that both are probabilistic and gameable with prompt rewrites: see the operational-reality callout further down. You cannot score at all at Level 1.
The trade-off, honestly: Level 3 is slower to build and harder to maintain. You own the data preparation, retrieval design, evaluation harness, and operational discipline. Level 1 is fast because someone else owns all that on your behalf, and gives you correspondingly less.
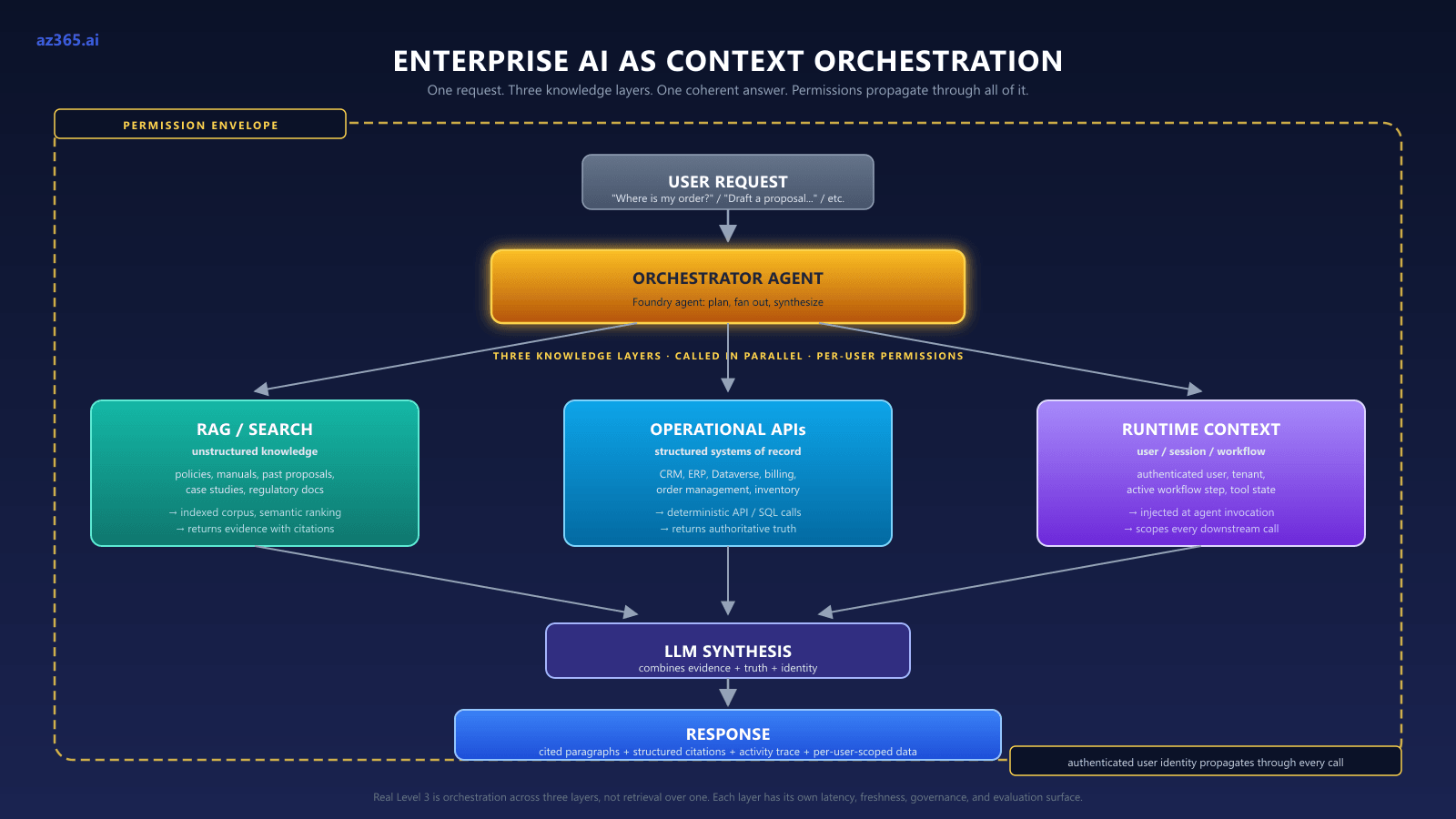
Level 3 in Practice: Three Knowledge Layers (RAG Is Only One of Them)

The biggest misread of “tailored AI” is treating it as a single retrieval problem. RAG retrieves relevant information. Operational systems establish authoritative state. Policy PDFs in your indexed corpus are guidance. The CRM is the authoritative state of who the customer is, what they bought, and what’s open. The active session is the authoritative state of who is asking right now and what they’re authorized to see. A Level 3 architecture that only retrieves documents will hallucinate the moment a user asks “where is my order?” or “is this customer past due?”
In production, Level 3 spans three knowledge layers and the orchestrator agent routes across all of them in a single permission envelope. Architect for all three.
Retrieval, Grounding, Authority: three distinct functions
A common confusion in production is treating retrieval, grounding, and authority as the same problem. They are not. Each has a different function, a different failure mode, and a different fix.
| Function | Purpose | Failure mode if confused |
|---|---|---|
| Retrieval | Finds potentially relevant information from a corpus | Confuse with authority and you cite a policy passage as the source of truth for current order status |
| Grounding | Constrains generation using retrieved evidence; evaluator-measurable | Confuse with retrieval and you assume the model uses what it retrieved (groundedness evaluator exists because it often doesn't) |
| Authority | Determines what is operationally true: the current state of the business | Confuse with retrieval and your agent confidently produces stale or wrong answers about live state |
RAG is retrieval. Groundedness evaluators are grounding. Systems of record are authority. Wire all three; treat them differently.
A nuance worth naming. The boundary between retrieval and authority is not always sharp in practice. Cached operational snapshots, event-stream projections, materialized views from systems of record, and hybrid retrieval that fuses indexed and live data all blur the line for legitimate latency or cost reasons. The discipline is not “never put operational data in an index”; it is “when you do, label what was authoritative at indexing time vs. what is authoritative now, and decide which the workload requires.” A cached order status from 30 seconds ago is fine for “show me roughly where my order is.” It is not fine for “process this refund.” The architect owns that distinction per workload.
A production enterprise AI system must inherit source-system permissions across all three layers. The authenticated user’s identity propagates from the request, through the orchestrator, through every retrieval call, every operational API invocation, and every runtime-context lookup. Skip this at any layer and the agent leaks data across users, tenants, or roles. The diagram above shows the propagation as the dashed yellow envelope; in code it’s the permission token threaded through every tool call.
| Knowledge layer | Example | Authoritative source | Best mechanism |
|---|---|---|---|
| Unstructured knowledge | policies, manuals, past proposals, case studies, regulatory docs | indexed corpus (curated and chunked) | RAG / agentic retrieval with semantic ranking + citation evidence |
| Structured operational state | orders, claims, invoices, customer records, inventory, deal status | systems of record (CRM, ERP, Dataverse, billing system) | deterministic API / SQL calls via agent tools; never paraphrased by the LLM |
| Runtime / user context | authenticated user, active workflow step, current session, tool state, recent actions | the request itself + session store | context injection at agent invocation; permissions trim every downstream call |
Runtime context goes deeper than “the user”
The runtime layer is the most under-engineered of the three in pilots we have reviewed. Beyond the authenticated user identity, a production-grade runtime context envelope carries:
- Workflow state: which step of a multi-step process the user is in, what’s been approved, what’s pending, what’s been rolled back.
- Ephemeral memory: the last few turns of conversation, any clarifications the user supplied, any preferences the agent has been told to remember for this session only.
- Active tool state: which tools the agent has invoked this session, what they returned, what’s been retried, what’s been escalated.
- Approval state: which actions are gated on human approval, which approvals are outstanding, who can grant them.
- Human escalation: the path back to a person when the agent can’t or shouldn’t act autonomously.
- Multi-agent coordination state: in multi-agent topologies, which agent is the current owner of the task and where its hand-off boundary is.
- Tenant isolation: which tenant the request belongs to, with the corresponding scoping on every downstream call.
Skip any of these and the agent has a partial picture of “who is asking and what they can do.” That’s where the loud production failures live.
Bounded autonomy: the operational constraint architects own
Agents can be reliable or they can be autonomous; pick one and design for it explicitly. Bounded autonomy is the architectural pattern that lets an agent act without permission to act everywhere:
- Scoped actions: every tool the agent can invoke is named, parameter-typed, and explicitly registered. No “freeform” tool calling.
- Typed action contracts: each tool defines its input schema, its output schema, and its side-effect class (read-only, mutating, externally observable). The orchestrator validates against these contracts before invocation.
- Permission-aware execution: every invocation is wrapped in the asking user’s permission envelope. The tool itself enforces; the agent does not.
- Human approval boundaries: actions above a configurable risk class route to human approval before execution. The agent proposes; a human commits.
- Blast-radius containment: actions that touch external systems (sending email, posting to a channel, updating a customer record) are gated behind explicit per-action allow-lists, rate limits, and rollback paths.
The architect’s job is to define the autonomy boundary explicitly. An “agentic” system without these boundaries works in pilots and surprises its operators in production; whether the surprise is mild or severe is a matter of luck rather than design.
A worked walkthrough: “Where is my order?”
The clearest test of whether your Level 3 architecture is real or theatre is this query. A pure-RAG agent fails on it. A correctly-layered agent answers in seconds with audit-defensible provenance.
- Runtime context layer resolves the asker. The agent receives the authenticated user identity, their tenant, their role, and any active conversation context. Without this, the agent has no idea which “my” the question refers to.
- Operational data layer queries the order system (or CRM, or ERP, depending on the workload) via a deterministic API call scoped to the authenticated user’s permissions. Returns the actual order record: status, ship date, tracking number, current location. Citation:
OrderID-2026-074118, fetched at timestamp X via the order API, RBAC-scoped to user Y. - Knowledge retrieval layer retrieves the shipping policy that explains what “in transit, regional sortation hub” means in plain language. Citation:
Policy-Shipping-v3.2, indexed copy of the customer-facing shipping policy. - Agent synthesis combines the three: “Your order #074118 is at the regional sortation hub in Memphis; per our shipping policy, that’s typically the last hop before final delivery, usually 24-48 hours away.” Each clause cites its source.
Three different authoritative sources. Three different access patterns. Three different governance regimes. One coherent answer.
This is what “agent orchestrates; deterministic layer calculates” actually looks like at production scale. The agent is the conductor. The systems of record carry truth. RAG carries explanatory context. Runtime injection carries identity.
Failure modes by layer
Each layer fails differently. The architect’s job is to know which failure looks like which.
| Layer | Typical failure mode | What the user sees | What the architect fixes |
|---|---|---|---|
| Knowledge retrieval (RAG) | Stale policies, missing recent updates, security-trimming gap, retrieval drift | Confidently-cited but outdated information | Index refresh cadence, security trimming against full identity matrix, groundedness evaluator gating |
| Operational data (systems of record) | API latency, expired permissions, mis-scoped tool call, schema drift | Empty result, permission error, or wrong customer's data | Tool-permission contracts, retry/timeout discipline, schema versioning in the agent tool wiring |
| Runtime context | Wrong authenticated identity, stale session, missing tenant scoping, leaked context across users | Other-user's data surfaces, or 'who am I?' fails | Identity propagation tests, session isolation, context-scrubbing between turns, audit of context-passing code paths |
Enterprise readers calibrate against failure boundaries more than conceptual purity. The above table is the one to screenshot when scoping a Level 3 build.
Observability: the architect’s evaluation surface
If you cannot replay what the agent did, you cannot debug it, defend it, or evolve it. ECA treats observability as a first-class architectural concern, not a logging afterthought. The instrumentation surface a Level 3 system needs:
- Traces: every retrieval call, every API call, every runtime-context lookup, every LLM call, with timing, token cost, return shape, and parent-child relationships across the whole turn.
- Replayability: any past request can be re-run against the current corpus, current evaluator suite, and current tool wiring to detect regression.
- Context lineage: for every claim in a response, which retrieved passage / which API response / which runtime variable contributed.
- Prompt provenance: the exact prompt template version, the exact retrieved context, the exact runtime envelope as the model saw it.
- Tool-call telemetry: per-tool success rate, latency p50/p95, error class distribution.
- Evaluation pipelines: groundedness, response-completeness, and task-specific evaluators running on a held-out set on every change, threshold-gating deploys.
This is what makes a Level 3 system defensible across releases. Without it, version drift is silent.
The user-facing question is usually phrased “should we train AI on our data?” The technical answer almost always means RAG, not fine-tuning. Synthesizing Microsoft’s RAG framing with the practitioner trade-offs we see in enterprise pilots:
| Choose RAG when | Choose Fine-Tuning when |
|---|---|
| Dynamic or changing content (org knowledge that updates) | Stable content that doesn’t need constant updates |
| Wide topic coverage across many domains | Task-specific performance on a narrow domain |
| Limited training data or compute budget | Lots of domain data + compute available |
| Need fresh answers, current information | Want consistent tone, style, format |
| Need source citations for audit | Citations not required |
For most enterprise scenarios where the goal is “answers grounded in our company’s knowledge,” RAG is the answer for grounding, with fine-tuning reserved for tone, voice, or narrow task automation. You can stack them, which is the apex of Level 3 and the subject of the next section.
When Fine-Tuning AND RAG Both Belong: The Tailored-Plus-Traceable Pattern
The “RAG vs fine-tuning” framing is convenient but wrong for the most demanding workloads. The right framing for the apex of Level 3 is fine-tuning AND RAG, layered. Microsoft explicitly supports this stack: combining fine-tuning with retrieval improves a model’s ability to integrate external knowledge and filter out irrelevant information, per the Foundry fine-tuning guidance.
Why fine-tuning alone fails the traceability test. A fine-tuned model has your data baked into its weights. It has internalized your patterns, your voice, your terminology, your historical decisions. Ask it where the answer came from and it cannot tell you, because the answer came from gradient updates on training data, not from a retrievable passage. There is no citation. There is no audit trail. There is no way to prove the model is grounded in current truth versus a six-month-old training cut. If your workload needs a source link next to every claim, fine-tuning alone moves you backward on the traceability axis, not forward. You traded the public web for your weights. Both are opaque to an auditor.
Why RAG alone leaves voice on the table. A pure-RAG agent retrieves the right passages but synthesizes them in whatever voice the base model defaults to. Fine for internal Q&A. Not fine for executive communications, brand-critical customer-facing content, regulated voice (legal opinions, regulatory filings), or anything where consistency of tone is a quality dimension. For those workloads you need the model trained on your voice while it is grounded in your facts.
The combined pattern, ordered. Microsoft’s RAG-or-fine-tuning architectural guide and the Foundry fine-tuning considerations treat these as composable. In practice the architecture sequences cleanly:
- Supervised fine-tuning (SFT) on voice / format / domain vocabulary. Train a LoRA fine-tune on representative examples that show the desired tone, formatting, and how the model should integrate retrieved citations. Training data is voice-and-format pairs, not factual knowledge. Foundry implements supervised fine-tuning using LoRA (low-rank adaptation), a parameter-efficient technique that is cheaper than full-weight retraining.
- Optional preference fine-tuning (DPO) on edge cases. Where SFT plus prompting leaves rough edges, Direct Preference Optimization lets you train on preferred-versus-rejected response pairs. Useful for “this response is correct but the wrong shape” cases.
- RAG / agentic retrieval layer on top. The fine-tuned model is now your base. Wrap it with the same agentic retrieval architecture as Level 3 RAG-only: indexed corpus, schema-aware subqueries, grounded synthesis, structured citations on every response.
- Groundedness evaluators run on the combined output. The eval target is whether the fine-tuned-plus-retrieving system cites the right passages and reflects current truth, not whether the fine-tune memorized historical patterns.
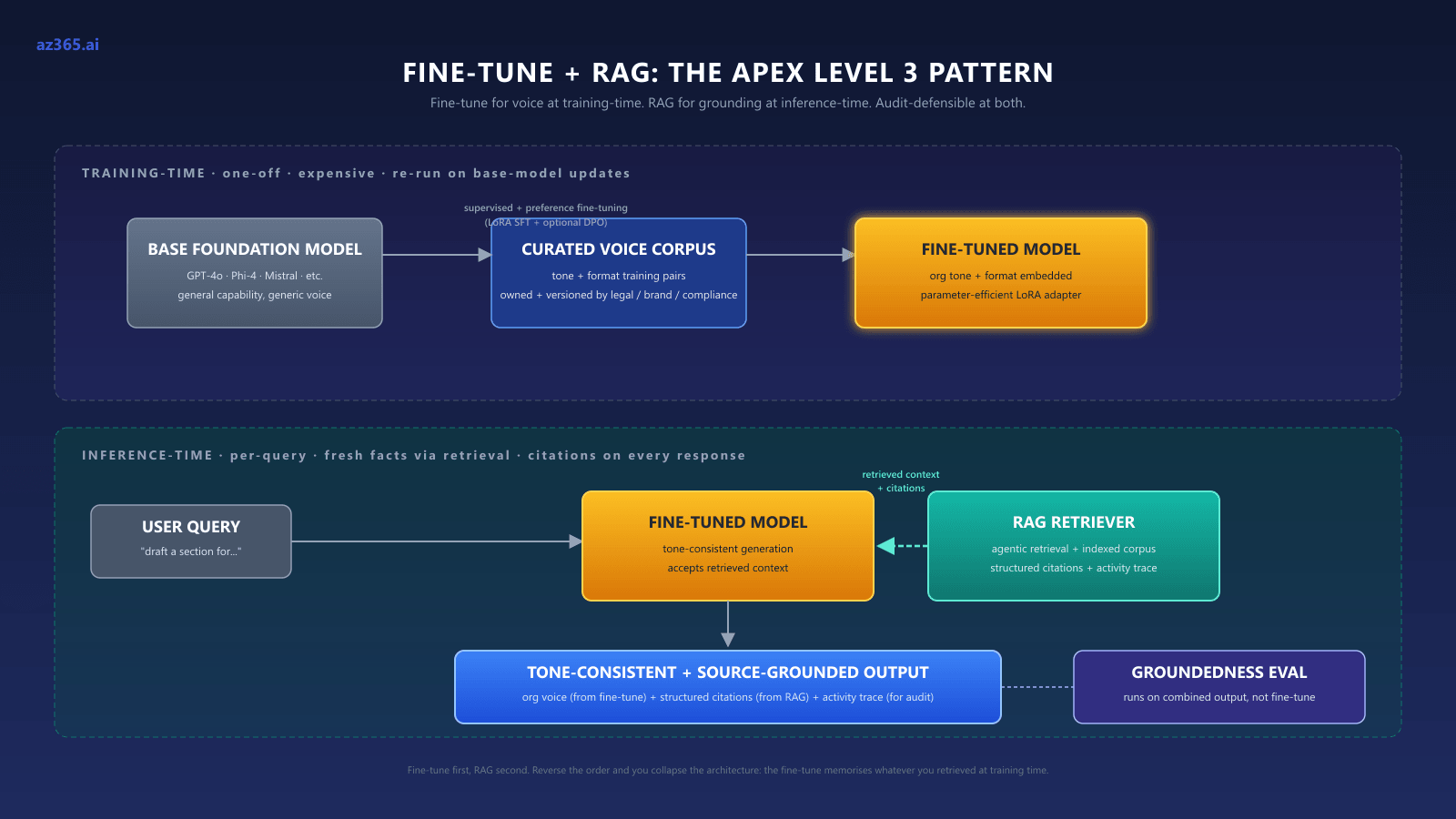
Why ordering matters. Fine-tune first, RAG second. If you RAG over a base model and then fine-tune that result, you collapse the architecture: the fine-tune memorizes whatever you retrieved at training time, freezing answers that go stale. Fine-tune for the layer that should stay stable (voice, format, instruction-following on retrieved context); RAG for the layer that should stay fresh (facts, citations, current state of the corpus).
When this pattern is right. Three workload types justify the cost:
- Regulated customer-facing communications (insurance claims responses, healthcare benefits explanations, financial-services advice memos): voice consistency is a regulatory expectation; traceability is a regulatory requirement. Both matter.
- Executive and corporate communications (annual reports, investor updates, official corporate responses): the C-suite voice must be consistent across documents; every factual claim must trace to underlying source data.
- Brand-critical content at scale (premium-brand marketing, partner communications, board reporting): the tone is a brand asset; the facts must be defensible.
When it is wrong. Most enterprise scenarios are not this. Internal productivity work, departmental Q&A, code completion, meeting summaries, research assistants, internal helpdesk: pure RAG (or Level 1 / Level 2) is the right answer. The combined pattern is expensive at training AND at inference, and only earns its keep when both voice and traceability are non-negotiable.
The honest cost shape. Fine-tuning on Foundry adds three operational lines that pure-RAG does not have. Per Microsoft’s stated fine-tuning challenges, the training set must be high-quality, sufficiently large, and representative of the target domain; poor data leads to over-fitting and bias. Beyond that:
- Training-data curation. Representative voice/format pairs. Building the training set is often the highest-effort step.
- Hourly hosting charge per deployed fine-tune. A deployed fine-tuned model incurs an hourly hosting cost regardless of inference volume. Foundry deletes deployments after 15 days of zero traffic but the artifact stays; production workloads keep the deployment hot, which is a recurring cost line absent from pure-RAG.
- Retrain cadence on base-model updates or training-data drift. When Microsoft ships a new base model you want to move to, you re-fine-tune. When your voice or domain examples change materially, you re-fine-tune. No equivalent retrain step exists in pure RAG; you just refresh the index.
The 2026 architect’s read on combined. In our experience, fewer than one in five enterprise workloads actually clears the combined-pattern bar. Of those that do, half attempt it, hit the training-data discipline wall, and roll back to RAG-only with stronger prompting on voice. The ones that ship and stay shipped are the ones with a named voice owner (legal, brand, compliance) maintaining the training set as a versioned artifact alongside the index.
In short: the “tailored AI trained on your data” framing is real, but the production-grade form of it is fine-tune for voice, RAG for grounding, evaluators on the combined output, named owner for the training set. The slogan version of “trained on your data” usually means “fine-tuned without RAG,” which is the version that fails the audit test.
Worked Example: AI-Assisted Proposal Writing at Level 3
Abstract three-level frameworks become believable when tied to a workload. The one we run through is proposal writing for a 40-person consulting firm responding to 8-12 RFPs per month.
The setup (illustrative scenario, composite of pilots we’ve reviewed). Past content lives across three systems: SharePoint (proposals, SOWs, case studies, reference letters), Dataverse (engagement records), and a Confluence wiki (technical approach templates). A senior consultant spends multiple days per proposal assembling content, often mis-citing past stats, missing recent wins, or quoting the wrong client. Win rates on RFPs requiring detailed past performance are well below where the firm wants them.
Why Level 1 fails. ChatGPT Enterprise or M365 Copilot will generate a plausible-sounding proposal. It will hallucinate client names, invent project durations, and quote ROI figures that exist nowhere in your actual delivery record. Every claim needs human verification, which means the consultant is doing the same assembly work as before plus correcting fabricated claims. Net productivity: marginal or negative.
Why Level 2 falls short. A Copilot Studio agent with knowledge sources pointing at the SharePoint proposal library partially works. It can retrieve relevant past proposals when asked. But it does not cite specific paragraphs reliably, drifts toward LLM-generated filler outside the retrieved scope, and cannot tell you which past engagements are most relevant by industry / deal size / scope match. Compliance review of the draft is still required because you cannot trace every claim back to a verifiable source.
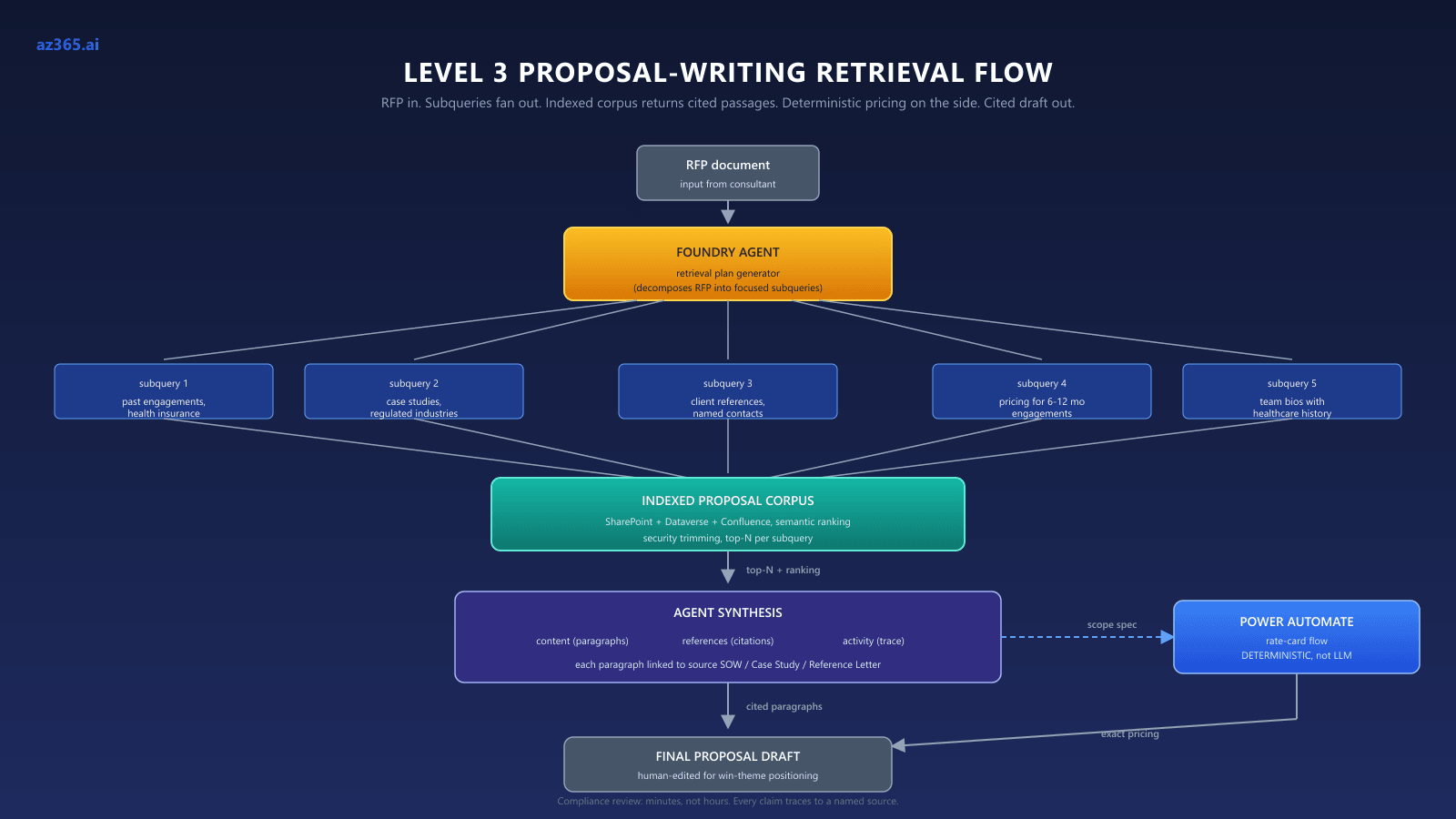
Why Level 3 works. A Foundry agent with agentic retrieval over an indexed proposal corpus produces the following flow:
- Consultant feeds the RFP to the agent: “Draft a response to this RFP for a regional health insurer. Required sections: technical approach, past performance, references, project plan, pricing approach.”
- The agent’s retrieval plan generates focused subqueries: “past engagements in health insurance,” “data migration case studies for regulated industries,” “client references with named contacts,” “pricing approaches for 6-12 month engagements,” “team bios with healthcare project history.”
- Each subquery runs against the indexed proposal corpus with semantic ranking. Top-N passages return with full source citations (SOW #2024-118, Case Study CS-2023-Q3-Health, Reference Letter RL-Acme-2024).
- The agent synthesizes section drafts, each paragraph linked to the source passages that grounded it.
- The activity array shows every subquery run, every passage retrieved, every ranking score. Compliance review takes minutes, not hours.
- Pricing is computed deterministically via a Power Automate flow that pulls actual past-engagement rate cards, not estimated by the LLM.
- The consultant edits the draft for win-theme positioning (the human strategic value-add) instead of assembling content.
The end-to-end flow is below: RFP in, subqueries fan out, corpus returns ranked passages with citations, synthesis branches to deterministic pricing on the side, cited draft out.
A sketch of the retrieval contract the agent works against, in pseudocode:
// Agentic retrieval contract (Foundry-style, simplified)
type ProposalSubquery = {
intent: "past_engagement" | "case_study" | "reference" | "pricing" | "team_bio";
filters: {
industry?: string; // "health_insurance"
dealSizeUsd?: [number, number]; // [250_000, 2_000_000]
technology?: string[]; // ["dataverse", "power_automate"]
sharableExternally: true; // never retrieve NDA-restricted content
};
topN: number; // pagination, default 5
};
type RetrievalResponse = {
content: string; // synthesized passage
references: SourceRef[]; // each citable: SOW-2024-118, CS-2023-Q3-Health
activity: SubqueryTrace[]; // every subquery + ranking score + token cost
};
// Pricing is NEVER computed by the LLM
function computePricing(scope: ScopeSpec): PricingResult {
return powerAutomateFlow.invoke("rate-card-pricing", scope);
}The contract is the discipline. Every retrieval pass returns content + references + activity. Pricing always routes to deterministic compute. The agent orchestrates; the deterministic layer calculates.
The named architectural choices that make this work:
- Curated index, not raw dump. The proposal corpus is preprocessed: dedup, anonymization where appropriate, tagged by industry / scope-size / outcome / technology stack. Garbage in = grounded garbage out.
- Schema-aware retrieval. Subqueries scope by industry first, then deal size, then technology. Not a flat similarity search across everything.
- Groundedness evaluators in CI. Each agent release runs the groundedness evaluator against a held-out set of past RFPs. Drops below 90% block deploy.
- Deterministic pricing. The agent never calculates rate-card math; it calls a flow that does.
- Audit trail. Every proposal sent has its retrieval activity log archived. If a claim is later challenged, the source is traceable.
The realistic operational outcome (illustrative). Three things change. Proposal turnaround drops from multi-day to half-day of senior consultant time. Win rate improves modestly because proposals reference the right past wins with the right specifics. Every claim is source-traceable, which makes legal review faster and procurement requests answerable.
This is not a marketing-slogan outcome (“AI writes your proposals”). It is the outcome architects can defend to a managing partner. Multiplier numbers depend on corpus quality, retrieval design, and how much rework the agent saves the senior reviewer; pilots we have reviewed land at very different points along this range, so we decline to quote a single percentage.
What broke in the pilots, honestly. Level 3 is not failure-free. The two failure modes we see most often: the agent’s subquery generator producing overly-broad initial queries that return passages from out-of-scope industries (fixed by adding a filters_required guardrail before subquery dispatch), and security-trimming gaps surfacing only when a guest auditor account ran the agent during user-acceptance testing (fixed by re-running security trimming against the full identity matrix, not just internal accounts). Neither is a Level 3 indictment; both are a reminder that operational discipline is where Level 3 earns its keep.
This is the pattern we wrote up in more depth in the AI Proposal Writing on Foundry article. The principle generalizes: any workload where claims need to be source-citable, RAG with agentic retrieval is the right substrate.
Which Architect Responsibilities Don’t Disappear at Level 3?
Adopting Level 3 does not absolve the architect of existing responsibilities. The platform makes audit defensibility possible; the work below makes it real. In our experience, these are the seven responsibilities the platform does not own for you.
| Responsibility | What the platform does NOT do for you |
|---|---|
| Semantic modeling of the source corpus | Decide which fields matter (industry tags, deal size, outcome, technology, named-client where shareable) and how proposals link to SOWs, case studies, and references. The retrieval is only as good as the model behind the index; the platform inherits whatever taxonomy you bring. |
| Data shaping discipline | Clean past content, deduplicate entities, choose a sensible chunking strategy. Microsoft's RAG documentation consistently positions content preparation, indexing strategy, and prompt design as the levers under your control. The platform indexes whatever quality you bring it. |
| Retrieval design | Schema-aware queries, security trimming so users only retrieve content they are entitled to, top-N pagination so the agent does not exhaust the context window. Without security trimming, RAG leaks competitive intel between client proposals. |
| Groundedness evaluation in CI | Run RAG evaluators against a held-out set on every change. Threshold-gate deploys. Without this, regressions ship silently. |
| Deterministic tooling for calculations | Agents produce probabilistic outputs. For anything that needs a correct number on the first try (pricing math, ROI projections, financial reconciliation, regulatory thresholds), wire deterministic logic via Power Automate flows, calculated columns, or external compute. Agent orchestrates; deterministic layer calculates. |
| Governance + RBAC propagation | DLP policy, Purview labels, audit-log review cadence. RBAC must propagate from the asking user through the agent through every tool call (RAG retrieval AND operational API AND runtime context). Indexed corpora often hold content classified differently than the surface application's user permissions. The platform enables Level 3; your governance discipline makes it safe. |
| Tenant isolation + version drift | For multi-tenant deployments (MSPs, multi-end-client consultancies, hosted SaaS), the index, the evaluators, and the audit log all need explicit tenant tagging. Version drift is a parallel risk: when the indexed corpus, the LLM base model, the evaluator suite, and the system-of-record schema all evolve on independent cadences, the architect owns the version compatibility matrix. Plan a versioning strategy or accept silent regressions. |
| Data residency + procurement | Confirm sovereign-region availability, customer-managed-key support for the index, and the contractual position on training-on-customer-data before you commit. Procurement-time friction is cheaper than mid-build replatforming. For regulated workloads (financial services, public sector, healthcare in EU/UK), the procurement model matters as much as the architecture. |
What Level 3 Will NOT Do for You (Eight Limits)
The “tailored AI on your data” framing implies more than it delivers. Skeptical readers will ask each of these:
- Level 3 does not mean “we trained AI on our data.” Tailored RAG retrieves from an indexed enterprise corpus at query time. The base model weights are unchanged (unless you also fine-tune, which is the combined pattern from earlier and a separate decision). When a stakeholder asks “did we train it on our data?”, the precise answer is “we indexed our data and the model retrieves from it per query, which is what you actually wanted because training would be slower to update and harder to audit.”
- RAG does not replace your data warehouse, lakehouse, or analytics substrate. Azure Data Lake, Fabric, and Synapse remain the right homes for high-volume analytics. The RAG index is downstream of these for grounding, not a substitute for them.
- RAG does not eliminate hallucinations. It narrows the gap between LLM output and source truth; it does not close it. Retrieval can return wrong passages, the LLM can synthesize incorrectly from correct passages, and the model can ignore retrieved context if your prompt design is weak. Groundedness evaluators catch most failures, not all.
- Level 3 is not “set and forget.” Index freshness, schema drift, retrieval quality, and groundedness scores all need ongoing operational discipline. We have seen meaningful groundedness drift over two-quarter windows when no one owns the eval harness. The exact decay curve depends on how fast your source corpus changes; the pattern is consistent.
- Not every workload needs Level 3. Most internal productivity work is fine at Level 1. Most departmental knowledge agents are fine at Level 2. Level 3 is for workloads where audit defensibility matters: proposals, claims, regulatory response, financial reporting, customer-facing communications, anything that goes into a legal record.
- Level 3 is not a replacement for governance. DLP, Purview, RBAC, audit log review still apply. The platform makes grounded answers possible; governance makes them safe.
- Level 3 is not sufficient without deterministic tooling. Agents are probabilistic. Calculations, regulatory thresholds, and any numeric output that must be correct on the first try should be computed by deterministic tools called by the agent, not by the LLM.
- Level 3 is not autonomous AI. A Level 3 agent is more accurate than a Level 1 chat. It is not a reliable autonomous worker. Human-in-the-loop, evaluation gates, and fallback flows still apply.
Each of these limitations is what your audit committee, compliance lead, or procurement officer will eventually ask about. Better to scope around them now than to discover them in production.
Decision Frame: When Each Level Is Right
Six workload archetypes mapped to levels. Find yours. The decision tree below collapses the table into three questions; the table after it carries the detail.
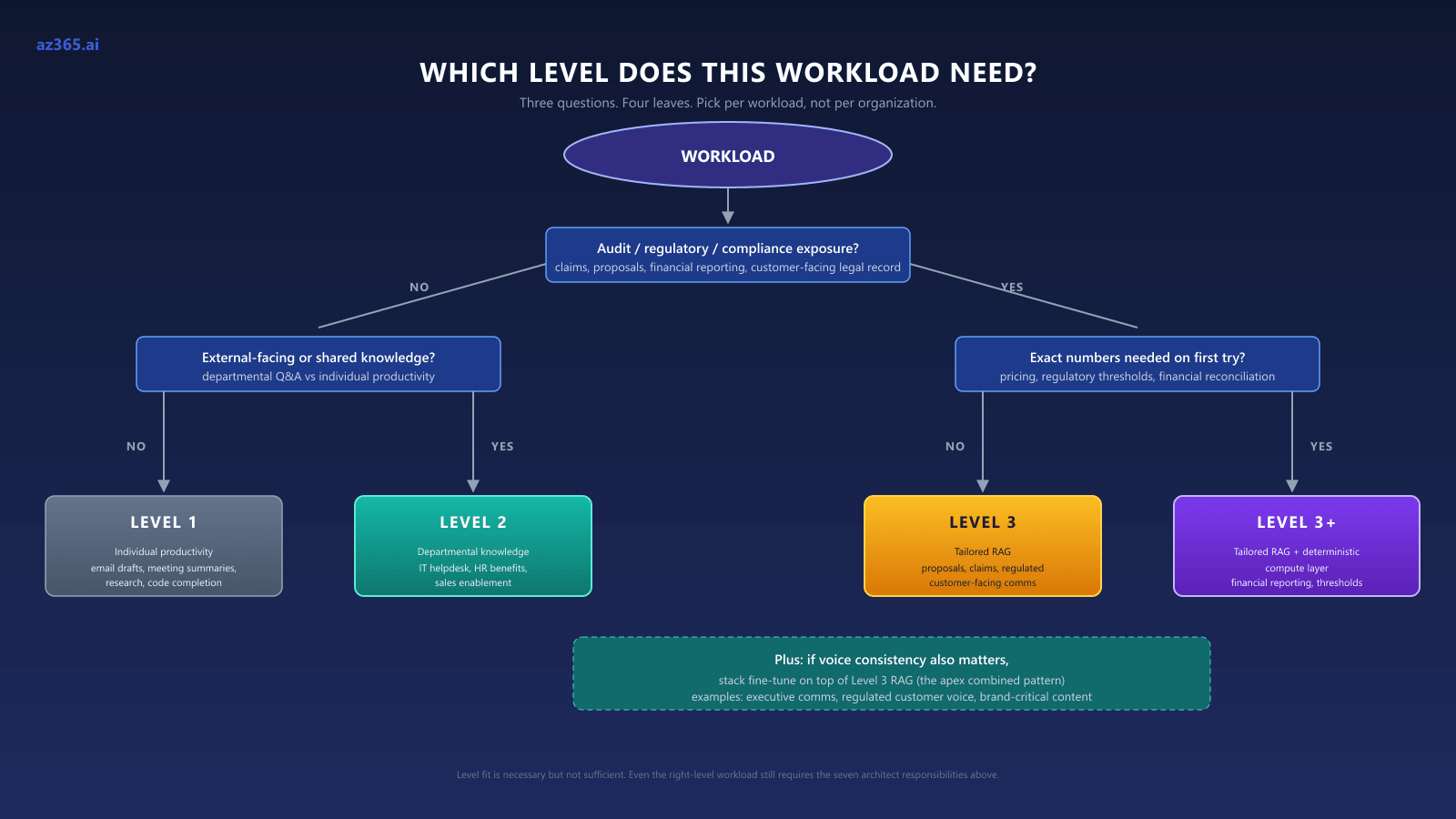
Level fit is necessary but not sufficient. Even the right-level workload still requires the seven architect responsibilities above (semantic modeling, retrieval design, evaluators in CI, deterministic tooling, governance, data residency, training-set ownership if you fine-tune).
The reference table:
| Workload | Right level | Why | Common mistake |
|---|---|---|---|
| General productivity (email drafting, meeting summaries, code completion) | Level 1 | Speed + cost + low audit risk. The training-data-blend trade-off is acceptable. | Building custom RAG when M365 Copilot would have shipped in a week |
| Departmental knowledge Q&A (IT helpdesk, HR benefits, sales enablement) | Level 2 | Knowledge-source-scoped agents in Copilot Studio cover this cleanly. Connector retrieval gives partial grounding. | Stopping at Level 2 for workloads that actually need audit defensibility (compliance, claims) |
| Regulated customer-facing comms (proposals, claims, insurance, legal response) | Level 3 | Every claim must be source-traceable. Compliance review takes minutes only with structured citations. | Building at Level 1 or 2 and discovering at audit time that nothing is provable |
| Financial reporting + executive summaries | Level 3 + deterministic layer | Numbers must be exact. RAG for narrative + deterministic compute for math. Tone-fine-tuning optional. | Letting the LLM do arithmetic |
| Field operations (inspection, dispatch, technician guidance) | Level 2 or 3 | Depends on whether the field action has audit/regulatory exposure (then Level 3) or is internal-only guidance (Level 2 suffices). | One-size-fits-all; same agent design for low-risk internal vs regulated external |
| Internal R&D / experimentation / prototyping | Level 1 | Fast iteration > audit defensibility. Promote to Level 2 / 3 when prototypes become production. | Promoting a Level 1 prototype to production without re-architecting |
The pattern: pick the level per workload, not per organization. Most enterprises will run all three levels simultaneously, with the architecture team owning the boundary decisions.
When Does Each Level Fail? Transition Triggers Between Levels
Enterprise architects do not want a maturity ladder. They want decision triggers, concrete signals that the current level has run out of headroom and the workload needs to advance. The triggers below are the ones we see force level transitions in pilots we have reviewed.
| Current level | Trigger that forces advancement | What it costs to advance |
|---|---|---|
| Level 1 → Level 2 | The workload starts producing externally-visible content (departmental Q&A, customer-adjacent), or stakeholders begin asking for source citations the M365 Copilot blend cannot reliably provide. | Copilot Studio + Managed Environments + ALM discipline + knowledge-source curation. Real but bounded cost. |
| Level 2 → Level 3 | Compliance, legal, or procurement starts asking 'where did that claim come from?' and the connector-citation answer is no longer sufficient. Or the corpus grows past the connector retrieval quality envelope. | Foundry agent build + indexed corpus + agentic retrieval + groundedness evaluator harness + CI gating. New operational discipline; new observability burden. |
| Level 3 → Level 3 + fine-tune | Voice consistency becomes a regulatory or brand-quality requirement (regulated customer comms, executive voice, brand-critical content at scale) AND retraining cadence is acceptable. | LoRA SFT + optional DPO + ongoing voice-corpus ownership + hourly fine-tune hosting + retrain on base-model updates. Highest operational cost in the stack. |
The trigger column matters more than the cost column. If the trigger has not fired, advancing is over-engineering. If the trigger has fired, staying at the current level is technical debt accruing toward an audit incident.
When Should a Copilot Studio Agent Move to Foundry?
For Power Platform teams already running Copilot Studio agents with knowledge sources, the practical question is not “Level 2 or Level 3?” abstractly. It is “do we extend the existing agent, or rebuild it?” In our experience the decision turns on three concrete tests.
Extend in Copilot Studio (stay Level 2) when the workload tolerates connector-source citations without structured grounding metadata, when knowledge-source documents change slowly enough that connector refresh windows are acceptable, and when the agent’s output is reviewed by humans who can verify claims themselves. Add Azure AI Search as a connector if you need broader corpus coverage; this stays a Level 2 deployment with stronger retrieval, not a Level 3 architecture.
Rebuild in Foundry (move to Level 3) when the workload requires structured citation evidence on every response (compliance review, regulated comms), when you need groundedness evaluators gating CI deployments, when you need the activity-array audit trace, or when the corpus is large enough that connector-style retrieval no longer ranks well.
The breakpoint is the audit posture, not the model behind the agent. A Copilot Studio agent and a Foundry agent can both call the same underlying model; what differs is the response contract (does it return structured grounding data and activity trace?) and the operational discipline (is there a groundedness evaluator gate on every release?). If the answer to either is “no,” the agent is at Level 2 regardless of model choice. If the workload requires “yes” to both, plan a Foundry rebuild, not an extension.
For Managed-Environments-deployed Power Platform tenants, the rebuild has an additional discipline layer: ALM, solution packaging, environment routing, and CoE governance approval cycles. Plan the Foundry build inside the same ALM regime, not as a separate stream.
How Should Your 2026 AI Architecture Plan for All Three Levels?
In our read, the three-level framing is more useful than the five-level CMM maturity model Microsoft publishes for adoption. The CMM model measures the organization. The three levels measure the workload. The organization-level view is for change-management leads; the workload-level view is for architects making build decisions.
The deeper signal we are watching: in our read, traceability is becoming the primary differentiator between AI that ships demos and AI that ships production systems. Level 1 wins on speed-to-demo. Level 3 wins on speed-to-audit. Both have valid use cases. The category in the middle (Level 2) is where most enterprises sit and most regret-investments live: enough customization to claim “we built our own AI,” not enough citation discipline to actually defend it.
The architect’s question is not “which level should we adopt?” It is “which level does each of our workloads actually need, and are we building each one at the right level?”
Enterprise AI Anti-Patterns: What Fails in Production
Naming the failure modes is more useful than naming the successes. These are the patterns we see fail repeatedly in pilots and the early-production stage. If your architecture has any of them, the audit is going to surface them, so better to surface them yourself first.
- Vector database as universal truth layer. Treating the indexed corpus as the source of “what is currently true” instead of as the source of “what we wrote down at some point in the past.” Order status, account balances, deal state: none of those belong in a vector index. They belong in systems of record, queried at request time.
- Stateless agents in stateful workflows. An agent that forgets the approval that was granted three turns ago, or the prior tool call that already moved the workflow forward. Runtime context is not optional infrastructure.
- Direct model-to-ERP writes. Letting the LLM generate the payload and call the mutation endpoint without typed contracts, validation, or human approval boundaries. The first regression silently corrupts production data.
- Missing permission inheritance. RBAC enforced at the surface application but not propagated to the retrieval call, the API call, or the runtime-context lookup. The agent leaks across users the moment one of those calls runs unscoped.
- Prompt-only orchestration. Trying to control which tool the agent picks, in what order, with what guardrails, entirely through prompt engineering. Works in demos. Fails under adversarial input, fails under multi-tenant load, fails under workflow complexity. Wire the orchestration logic deterministically; let the LLM only choose within the bounded option set.
- Unbounded agent autonomy. “Let the agent figure it out” without scoped actions, typed contracts, or human approval boundaries. This is how blast-radius incidents happen.
- Groundedness evaluators as a compliance fig leaf. Running the evaluator suite for the audit committee then ignoring its output because it gates deploys. Either the threshold gate is real and slows you down, or it is theatre.
- Treating retrieval quality as fixed. Building the index once at project kickoff and never re-indexing as the source corpus drifts, the chunking strategy reveals its weaknesses, or the ranker improves. Retrieval is an operational discipline, not a one-time setup task.
- One global evaluator for all workloads. Workload-specific evaluation harnesses don’t share thresholds. Proposal-writing groundedness and customer-claims groundedness need different gold sets and different bars.
- Observability as a logging afterthought. Tracing the LLM call but not the retrieval plan, the tool invocations, or the runtime envelope. The next incident debugging session will reveal the gap.
Each of these is recoverable if caught early. The hard ones are the ones that ship to production unnoticed and only surface during an audit or an incident.
The Hard Part Is Often Organizational, Not Architectural
Most of this article has been about architecture: layers, contracts, evaluators, observability, autonomy boundaries. That is the part architects can solve directly. It is also, honestly, not where most enterprise AI programs actually fail. Where they fail, in our experience:
- Ownership ambiguity. Who owns the indexed corpus? Who owns the evaluator harness? Who owns the prompt? Who owns the agent’s autonomy boundary? In federated enterprises, these often have no single owner, and the resulting drift is invisible until an incident.
- Continuously evolving business semantics. The org’s definition of “customer,” “active,” “open,” “approved,” “in good standing” shifts as products, regulations, and acquisitions change. Every shift breaks something downstream. The architecture cannot freeze meaning that the business keeps redefining.
- Conflicting ownership domains. The CRM is owned by Sales; the ERP is owned by Finance; the indexed corpus is owned by IT; the Foundry environment is owned by a Cloud CoE. Each has its own change cadence and approval process. An ECA spanning all of them is, in practice, four different change-management cycles stitched together.
- Procurement friction. The contract for the model endpoint, the contract for the search service, the contract for the evaluator product, and the contract for the agent runtime are often four separate procurement cycles. By the time all four close, the architecture has shifted underneath.
- Legal review cycles. Data residency, training-on-customer-data clauses, indemnity for grounded-output errors, regulatory disclosure, retention policy on activity logs: each of these is a separate review, often with different approving counsel.
- Operational support burden. A Level 3 system has a 24x7 operational shape if customers depend on it. Most enterprises do not have an existing on-call rotation for “the agent’s eval harness drifted overnight.” That capability has to be built.
- Internal platform fragmentation. Multi-BU enterprises rarely have one CRM, one ERP, one identity provider. They have versions of each. The ECA’s “operational APIs” layer is sometimes five APIs that each return the same field with a different name.
The honest architectural admission. Perfect context orchestration can itself become a bottleneck. A sufficiently centralized ECA can become the single point of slowness that every workload routes through. A sufficiently federated one becomes a coordination problem where no single team can ship an end-to-end change. Architects who have lived through both extremes will recognize this tension; there is no clean answer, only the workload-by-workload calibration the article has argued for throughout.
The technical disciplines in this article are necessary. They are not sufficient. The enterprise AI programs that ship and stay shipped are the ones with named owners per layer, explicit semantic-versioning of business definitions, a cross-domain coordination function, and patience for the procurement and legal cycles that the technology itself cannot accelerate.
The Position, Stated Plainly
Enterprise AI is not a single retrieval problem. It is the orchestration of multiple context systems with different latency, authority, freshness, and governance characteristics. Everything else in this article is a corollary.
The corollaries, distilled:
- RAG ≠ enterprise AI architecture. RAG is one knowledge layer (unstructured). Real Level 3 systems also call structured systems of record and inject runtime context. Architect for three layers, not one.
- Pick the level per workload, not per organization. Most enterprises run all three levels simultaneously. The architecture team owns the boundary decisions.
- Traceability is the apex axis. Level 1 wins on speed-to-demo. Level 3 wins on speed-to-audit. The combined fine-tune + RAG pattern wins on both audit and voice. Each has valid use cases; choose by what the workload actually demands.
- Operate three layers with different disciplines. Retrieval, operational API calls, and runtime context have different latency budgets, freshness requirements, governance regimes, and evaluation surfaces. A Level 3 architecture that uses the same operational discipline across all three is under-engineered.
- Permissions propagate through every layer. RBAC must flow from the asking user through the agent through every tool call. DLP, Purview, tenant isolation, and version drift all apply across all three layers, not just the LLM.
- The agent orchestrates; the deterministic layer calculates. Numbers come from systems of record or deterministic compute, never from the LLM. Citations come from RAG. Identity comes from runtime context. The agent is the coordinator, not the source.
Build to that bar and Level 3 is a system you can defend in an audit, not a slide you defend to procurement after the contract is signed.
The directional close. The future enterprise AI stack will not be defined primarily by the model layer. The model layer will commoditize. It will be defined by how reliably organizations manage context, authority, permissions, and execution across distributed systems, by their Enterprise Context Architecture. That is the durable architectural lane. Build into it.
Glossary: Terms in This Article
- Agentic retrieval: a retrieval pattern where an LLM-driven agent decomposes a complex question into focused subqueries, runs them against an indexed corpus in parallel, and returns structured grounding data with citations and execution metadata. Distinguished from classic single-query RAG by its subquery planning and structured response format.
- Groundedness evaluator: an automated test that scores whether an LLM response cites only the retrieved context, or fabricates outside it. Microsoft Foundry exposes this as a first-class RAG evaluator with a numeric score.
- Foundry IQ: Microsoft’s umbrella for Foundry-native retrieval, knowledge stores, and evaluator tooling that sits under Foundry agents.
- Tailored RAG: our shorthand for Level 3 in this article: RAG over a curated, indexed enterprise corpus with agentic retrieval, security trimming, groundedness evaluation, and deterministic tooling for calculations. Not a Microsoft product name.
- Security trimming: filtering retrieved passages by the requesting user’s permissions so the agent never returns content the user cannot legitimately see. Implemented at the index level, not at the LLM level.
- Activity array: the trace of subqueries, retrieval calls, and ranking scores returned alongside the synthesized answer. Used as the audit-log substrate for Level 3 responses.
- LoRA fine-tuning: low-rank adaptation, the parameter-efficient fine-tuning technique Foundry uses by default. Trains a small adapter on top of the base model rather than re-training the full weight matrix; cheaper, smaller artifact, faster to deploy.
- Knowledge retrieval layer (RAG / unstructured): the substrate that holds documents, policies, manuals, past work product. Authoritative for “what does our policy say” but not for “what is the current state.” Mechanism: agentic retrieval over an indexed corpus.
- Operational data layer (structured / systems of record): the substrate that holds the authoritative state of the business: orders, claims, invoices, customer records. Mechanism: deterministic API or SQL calls scoped to the asking user’s permissions. Never paraphrased by the LLM.
- Runtime context layer: the substrate that holds who is asking, what tenant they belong to, what they are authorized to see, what workflow step they are in. Mechanism: context injection at agent invocation; passed through every downstream tool call as the permission envelope.
- Version drift: the silent failure mode where the indexed corpus, the base LLM, the evaluator suite, and the systems-of-record schemas evolve on independent cadences and the agent’s behavior changes without anyone noticing. Mitigated by versioning each component and running the evaluator harness on every release.
Related Reading
- Azure AI Foundry vs Azure OpenAI: The 2026 Decision - the platform decision under Level 3 builds
- Dataverse MCP, Business Skills, and Coding Agents: The 2026 Decode - Dataverse-as-agent-data-platform is a Level 3 substrate for Microsoft business-apps workloads
- AI Proposal Writing on Foundry: Multi-Model Patterns That Ship - the deep version of the proposal-writing example above
- Claude on Azure: The Marketplace Billing Trap - the procurement reality of building Level 3 with multi-AI models on Azure
If you are mapping enterprise workloads to AI levels and want a second-opinion review of where each one belongs, reach out.
Stay in the loop
Get new posts delivered to your inbox. No spam, unsubscribe anytime.
Related articles
Azure AI Foundry New vs Classic: 2026 Migration Map
Azure AI Foundry new vs classic, decoded: the feature-parity matrix, what transfers in a hub migration, the two hard 2026 dates, and when to stay on classic.
From Assist to Execute: The Reference Architecture Implications Microsoft's Playbook Doesn't Draw (2026)
The Assist-to-Execute shift in Microsoft's Agentic Patterns Playbook is the right conceptual move. This is the reference architecture implications the playbook stops short of drawing.
The Scale-Breaker Microsoft Doesn't Name: Why Your AI Program Stalls Where the Playbook Doesn't Look (2026)
Microsoft's 2026 Agentic Patterns Playbook names five capability drivers. The scale-breaker most enterprises actually hit is the sixth one the framework doesn't measure.